Index Explains: Streaming TV
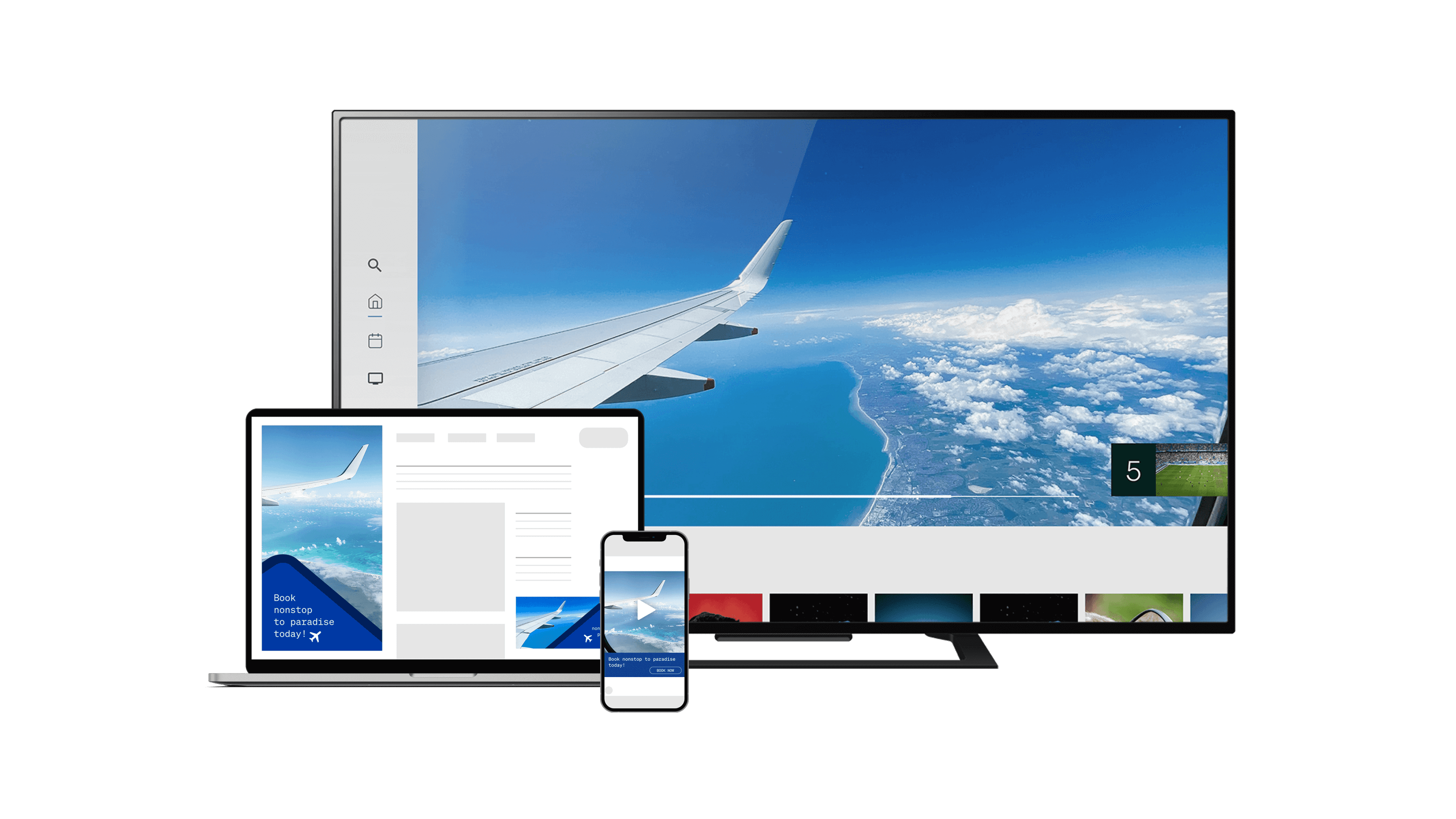
Videowerbung ist zwar anspruchsvoll, aber sie muss nicht verwirrend sein. In unserer neuen Videoreihe erklären wir, was es mit dem Streaming-TV auf sich hat.
Jetzt ansehenErkennen Sie den wahren Wert von Streaming TV über unseren dynamischen Marketplace, der für eine präzise Auslieferung und effiziente Maximierung der Erträge konzipiert ist.



Videowerbung ist zwar anspruchsvoll, aber sie muss nicht verwirrend sein. In unserer neuen Videoreihe erklären wir, was es mit dem Streaming-TV auf sich hat.
Jetzt ansehen
Unser Ad Exchange ermöglicht es Medienunternehmen, ihre Einnahmen zu steigern, und Vermarktern, Verbraucher auf jedem Bildschirm und mit jedem Werbeformat zu erreichen.

Wir haben uns dem Aufbau eines sicheren und transparenten Omnichannel-Marktplatzes verschrieben, der Verbrauchern ein vertrauenswürdiges Erlebnis bietet

In unserer neuen Blog-Reihe „Behind the Tech“ (Ein Blick hinter die Technik) werfen wir einen Blick hinter die Kulissen unseres …
Weiterlesen
Aktualisierung: Ab dem 16. April 2024 ist das Topics API Reporting auch in der Index UI verfügbar. Da wir mit …
Weiterlesen
Als das OpenRTB 2.6 Protokoll Anfang 2022 veröffentlicht wurde, bot es eine Reihe neuer Funktionen, die versprachen, die programmatische Werbung …
WeiterlesenNehmen Sie Kontakt auf, um zu erfahren, was Index für Sie tun kann.
Kontaktieren Sie uns